Hello everyone!
I finally got a chance to play with my Photon from particle.io, and I had been using the dashboard to debug my events..
I have a snipit of code that uses the provided OneWire library to read the temp from all of the sensors attached to my photon, and one by one 'Publish' a key/value pair to the particle API. I was using the OneWire address in hex as the key, and the temp in fahrenheit as the value. This would allow me to later create a mapping of which sensor was located where, but didn't need to be hard-coded into the firmware of the device.
I learned about two things today, both from the particle cli tool: particle subscribe mine and particle serial monitor
particle serial monitor lets me read the Serial.print* statements from my photon if I have it plugged in with a usb cable. I was previously opening up the editor to do this (while actually editing my code in the slick web IDE).
particle subscribe mine is a way to subscribe to all events produced by your devices on your account. Since my events are dynamically named based on the OneWire address, I didn't have a direct name to subscribe to. I'll have to create a service to read in the values from my sensors and log them for later processing.
Happy Hacking!
Sunday, November 8, 2015
Friday, October 23, 2015
Why is bash-complete so slow!
So, I've been using home-brew for a little while on my macbook, and I noticed that after I installed a few things with it, my tab completion was REALLY slow.... A little poking around was in order.
First I looked in my ~/.bash_profile, and I saw the following
if [ -f $(brew --prefix)/etc/bash_completion ]; then
. $(brew --prefix)/etc/bash_completion
fi
That pointed me in the direction I needed to go... Lets run the subtle command to see where it points!
MacBook-Pro-2:puppet-sandbox dawiest$ brew --prefix
/usr/local
So lets see how many files (and lines) are contained in those files..
MacBook-Pro-2:bash_completion.d dawiest$ ls /usr/local/etc/bash_completion.d/ | wc -l
186
MacBook-Pro-2:puppet-sandbox dawiest$ find /usr/local/etc/bash_completion{,.d/*} |xargs wc -l | grep total
wc: /usr/local/etc/bash_completion.d/helpers: read: Is a directory
25412 total
Holy smokes! 186 files, with 25k lines! No wonder it takes so long!
After I opened up the list of files in the bash_completion.d/ directory, removed the ones I didn't care about (they are all just symlinks pointing back to ../../Cellar/bash-completion/1.3/etc/bash_completion.d/), my auto-complete's in my shell are noticeably faster!
MacBook-Pro-2:puppet-sandbox dawiest$ ls /usr/local/etc/bash_completion.d/ | wc -l
50
MacBook-Pro-2:puppet-sandbox dawiest$ find /usr/local/etc/bash_completion{,.d/*} |xargs wc -l | grep total
wc: /usr/local/etc/bash_completion.d/helpers: read: Is a directory
14115 total
50 files, and 14k lines to execute, but I think I have removed the biggest offenders. I should figure out a way to profile each of the scripts to see how long they each take to source! It may be better to find the biggest offenders, and remove them if they aren't part of your usual command set.
Thursday, October 15, 2015
TiL - remember how to shell quote!
Just the other day, I was doing something over and over.... trying to kill a stubborn tomcat server that wouldn't gracefully die. sudo service tomcat stop just wouldn't cut it.
I was getting tired of repeatedly typing 'ps aux | grep tomcat', copying out the Process id, and passing it to kill -9. Time for some simple automation... an alias!
So, how to find the Process? First, we use ps to display a list of running processes, and the grep utility to select only the lines that contain tomcat.
My command looks something like this
Here is the updated command.
Most important note about the above command.... I initially forgot to use the single quote ('), and I accidentally used the double quote ("). What happens in that case is that your shell will try to do a variable substation, and replace $2 with the variable 2 ( which is usually used when you are passing arguments to a shell script, $0 is the name of the script, $1 is the first argument, $2 is the second, etc...). Since there was nothing in $2, it turned the awk command into 'print', which simply prints the entire line.
Here is the command without output using the wrong quotes.
Now, that will return only the PID... but what to do to it? I need to pass it as an argument to the kill command, so I'll run it in a subshell by putting it between two backpacks (`). I use the -9 argument to force kill to kill it totally. Remember to use sudo if you aren't running as the tomcat user!
My full command now looks like this
Remember to properly quote your shell variables, happy command line fu everyone!
I was getting tired of repeatedly typing 'ps aux | grep tomcat', copying out the Process id, and passing it to kill -9. Time for some simple automation... an alias!
So, how to find the Process? First, we use ps to display a list of running processes, and the grep utility to select only the lines that contain tomcat.
I needed to make sure I was only grabbing the tomcat process. Since I only have the tomcat server being run by the tomcat user, and the output of PS starts with the user who is running the process, I could use a regular expression that matches from the beginning of the line to the word tomcat. To make sure I can use the beginning of line char (^) in my regex, I use the '-E, --extended-regexp' argument.vagrant@client1:~$ ps aux | grep tomcattomcat7 6355 0.9 26.2 1050336 63972 ? Sl 00:37 0:04 /usr/lib/jvm/default-java/bin/java -Djava.util.logging.config.file=/var/lib/tomcat7/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.awt.headless=true -Xmx128m -XX:+UseConcMarkSweepGC -Djava.endorsed.dirs=/usr/share/tomcat7/endorsed -classpath /usr/share/tomcat7/bin/bootstrap.jar:/usr/share/tomcat7/bin/tomcat-juli.jar -Dcatalina.base=/var/lib/tomcat7 -Dcatalina.home=/usr/share/tomcat7 -Djava.io.tmpdir=/tmp/tomcat7-tomcat7-tmp org.apache.catalina.startup.Bootstrap start
vagrant 7504 0.0 0.3 10460 940 pts/0 S+ 00:46 0:00 grep --color=autotomcat
My command looks something like this
I then need to pull out the second record, which contains the process ID. For that, I use awk. It simply takes the output and breaks it into 'records', by default it uses whitespace. Using 'print $2' prints out the second record.vagrant@client1:~$ ps aux | grep -E '^tomcat'tomcat7 6355 0.7 25.6 1050336 62424 ? Sl 00:37 0:05 /usr/lib/jvm/default-java/bin/java -Djava.util.logging.config.file=/var/lib/tomcat7/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.awt.headless=true -Xmx128m -XX:+UseConcMarkSweepGC -Djava.endorsed.dirs=/usr/share/tomcat7/endorsed -classpath /usr/share/tomcat7/bin/bootstrap.jar:/usr/share/tomcat7/bin/tomcat-juli.jar -Dcatalina.base=/var/lib/tomcat7 -Dcatalina.home=/usr/share/tomcat7 -Djava.io.tmpdir=/tmp/tomcat7-tomcat7-tmp org.apache.catalina.startup.Bootstrap start
Here is the updated command.
vagrant@client1:~$ ps aux | grep -E '^tomcat' | awk '{ print $2 }'6355
Most important note about the above command.... I initially forgot to use the single quote ('), and I accidentally used the double quote ("). What happens in that case is that your shell will try to do a variable substation, and replace $2 with the variable 2 ( which is usually used when you are passing arguments to a shell script, $0 is the name of the script, $1 is the first argument, $2 is the second, etc...). Since there was nothing in $2, it turned the awk command into 'print', which simply prints the entire line.
Here is the command without output using the wrong quotes.
vagrant@client1:~$ ps aux | grep -E '^tomcat' | awk "{ print $2 }"tomcat7 6355 0.6 25.6 1050336 62424 ? Sl 00:37 0:05 /usr/lib/jvm/default-java/bin/java -Djava.util.logging.config.file=/var/lib/tomcat7/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.awt.headless=true -Xmx128m -XX:+UseConcMarkSweepGC -Djava.endorsed.dirs=/usr/share/tomcat7/endorsed -classpath /usr/share/tomcat7/bin/bootstrap.jar:/usr/share/tomcat7/bin/tomcat-juli.jar -Dcatalina.base=/var/lib/tomcat7 -Dcatalina.home=/usr/share/tomcat7 -Djava.io.tmpdir=/tmp/tomcat7-tomcat7-tmp org.apache.catalina.startup.Bootstrap start
Now, that will return only the PID... but what to do to it? I need to pass it as an argument to the kill command, so I'll run it in a subshell by putting it between two backpacks (`). I use the -9 argument to force kill to kill it totally. Remember to use sudo if you aren't running as the tomcat user!
My full command now looks like this
vagrant@client1:~$ sudo kill -9 `ps aux | grep -E '^tomcat' | awk '{ print $2 }'`When successful, this command has no output.
Remember to properly quote your shell variables, happy command line fu everyone!
Saturday, October 3, 2015
Arduino on OS X
Hi everybody!
Quick little blurb today..
Today I installed Arduino using homebrew/cask on my laptop, and was running into a little issue...
chmod: Unable to change file mode on /opt/homebrew-cask/Caskroom/arduino/1.6.5-r5/Arduino.app/Contents/Java/hardware/tools/avr/bin/avrdude_bin: Operation not permitted
Part of my issue was that I have an unusual homebrew install (installed with my 'admin' user, but my day to day user is not an admin).
I ended up following the steps outlined on this stackexchange post, and it didn't actually solve my problem, but it got my homebrew setup a lot happier for my non-admin user.
Then, I did the last thing any good programmer will do, and actually read what the error message was telling me! The arduino process was trying to chmod a file, which meant that it's mode must be incorrect...
I did an inspection of all the files in the avr/bin/ directory, and none of them had owner OR group execute permissions!
A quick little command fixed up my issue!
I can now load sketches to my Arduino, and connect to the serial port!
Thanks for reading everyone! I hope this helps someone with the same problem!
Quick little blurb today..
Today I installed Arduino using homebrew/cask on my laptop, and was running into a little issue...
chmod: Unable to change file mode on /opt/homebrew-cask/Caskroom/arduino/1.6.5-r5/Arduino.app/Contents/Java/hardware/tools/avr/bin/avrdude_bin: Operation not permitted
Part of my issue was that I have an unusual homebrew install (installed with my 'admin' user, but my day to day user is not an admin).
I ended up following the steps outlined on this stackexchange post, and it didn't actually solve my problem, but it got my homebrew setup a lot happier for my non-admin user.
Then, I did the last thing any good programmer will do, and actually read what the error message was telling me! The arduino process was trying to chmod a file, which meant that it's mode must be incorrect...
bash-3.2$ ls -la /opt/homebrew-cask/Caskroom/arduino/1.6.5-r5/Arduino.app/Contents/Java/hardware/tools/avr/bin/avrdude_bin-rw-rw-r-- 1 admin admin 369784 Apr 14 16:30 /opt/homebrew-cask/Caskroom/arduino/1.6.5-r5/Arduino.app/Contents/Java/hardware/tools/avr/bin/avrdude_bin
I did an inspection of all the files in the avr/bin/ directory, and none of them had owner OR group execute permissions!
A quick little command fixed up my issue!
bash-3.2$ chmod g+x /opt/homebrew-cask/Caskroom/arduino/1.6.5-r5/Arduino.app/Contents/Java/hardware/tools/avr/bin/*
I can now load sketches to my Arduino, and connect to the serial port!
Thanks for reading everyone! I hope this helps someone with the same problem!
Friday, September 25, 2015
Particle.io Photon!
Hi everyone!
I finally got a chance to play with my Particle Photon.
I finally got a chance to play with my Particle Photon.
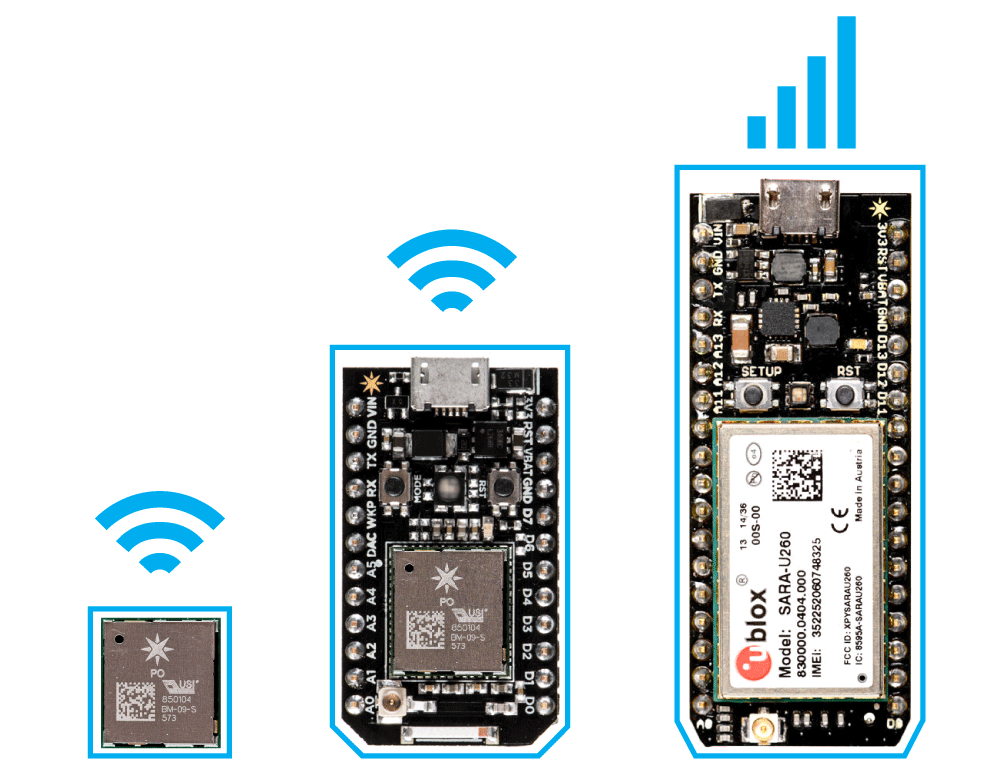 |
| Photon chipset (left), Photon dev board (center), Electron (right) |
I've had some prior experience with microcontrollers - and I decided to give the photon a try. It's a pretty neat platform. It comes set up with an onboard firmware/OS that once set up, will connect out to Particle's servers, and be accessible though their API.
Right out of the box, I hooked it up to power, downloaded the Particle app to my iPhone, and pointed my iPhone's wifi at the broadcast from the Photon. I was able to use the app to configure the photon with my home Wifi settings.
My Phone connected, and I selected pin D7 (the device has a built in LED on that pin). I told the pin to behave as a digitalWrite, this would allow me to toggle it between LOW and HIGH. When toggled low, the LED was off. When toggled high, the LED was on. Success!
I happened to have some buttons wired up to my small breadboard, and I wanted to verify the digitalRead action of another pin. I hooked pin D0 up to my button (which was connected between GND and VDD with a pull-up resistor).
The entire time, the D0 indicator on the app showed HIGH. Unplugged, plugged in, plugged in with button pressed or depressed. Is this not working? I tried connecting directly from D0 to GND, and D0 to VDD. Every time it reported HIGH.
I tried my Analog pin 0 (A0) and set it to analogRead. it reported 4095 (what I think is the equivalent to HIGH on the D0 pin). Hooked it up to ground, and the value didn't change!
Eventually in my plugging and unplugging of things, I ended up tapping on the A0 button on the iphone app, and I saw it's value change. I plugged D0 back into ground, and tapped D0 on the app, and it changed from HIGH to LOW. Ah ha! So it turns out that the app doesn't live update the values, you have to tap the button to see the update!
So... TL:DR; The iPhone Particle app doesn't live update, you have to tap on a pin set to digitalRead or analogRead to read the new value of the pin!
Now, time to start actually building something with it!
Friday, September 18, 2015
s3 ETag and puppet
Hello faithful readers!
Today, I ponder a problem... how to know if I have the latest version of a file from an s3 bucket, and how to get that logic into puppet?
Amazon s3 buckets can contain objects, which contain an ETag... which is sometimes the md5, and sometimes not..
In trying to figure out how to know if I should download an object or not, I was inspired by the s3file module out on the puppet forge.
https://github.com/branan/puppet-module-s3file/blob/master/manifests/init.pp
Notably, this slick shell command to pull out the ETag and compare it to the md5sum of the file..
"[ -e ${name} ] && curl -I ${real_source} | grep ETag | grep `md5sum ${name} | cut -c1-32`"
However, I saw that in my use case, we used aws s3 cp /path/to/file s3://bucketname/key/path/ and our uploads happen as multipart uploads at the low level. this makes our ETag break into multiple parts for files much smaller than the rest of the internet (I think at either 5mb or 15mb boundaries), which makes it not so keen for the above situation.
also, we don't have a publicly available bucket to curl, so we have to replace the curl -I call with a aws s3api head-object --bucket bucketname --key key/path/file.
While playing with the s3api command, I looked at a file I had uploaded previously. When I uploaded it, I had used s3cmd's sync option. I saw the following output.
Today, I ponder a problem... how to know if I have the latest version of a file from an s3 bucket, and how to get that logic into puppet?
Amazon s3 buckets can contain objects, which contain an ETag... which is sometimes the md5, and sometimes not..
In trying to figure out how to know if I should download an object or not, I was inspired by the s3file module out on the puppet forge.
https://github.com/branan/puppet-module-s3file/blob/master/manifests/init.pp
Notably, this slick shell command to pull out the ETag and compare it to the md5sum of the file..
"[ -e ${name} ] && curl -I ${real_source} | grep ETag | grep `md5sum ${name} | cut -c1-32`"
However, I saw that in my use case, we used aws s3 cp /path/to/file s3://bucketname/key/path/ and our uploads happen as multipart uploads at the low level. this makes our ETag break into multiple parts for files much smaller than the rest of the internet (I think at either 5mb or 15mb boundaries), which makes it not so keen for the above situation.
also, we don't have a publicly available bucket to curl, so we have to replace the curl -I call with a aws s3api head-object --bucket bucketname --key key/path/file.
While playing with the s3api command, I looked at a file I had uploaded previously. When I uploaded it, I had used s3cmd's sync option. I saw the following output.
$ aws s3api head-object --bucket bucketname --key noarch/epel-release-6-8.noarch.rpm { "AcceptRanges": "bytes", "ContentType": "binary/octet-stream", "LastModified": "Sat, 19 Sep 2015 03:27:25 GMT", "ContentLength": 14540, "ETag": "\"2cd0ae668a585a14e07c2ea4f264d79b\"", "Metadata": { "s3cmd-attrs": "uid:502/gname:staff/uname:~~~~/gid:20/mode:33188/mtime:1352129496/atime:1441758431/md5:2cd0ae668a585a14e07c2ea4f264d79b/ctime:1441385182" }}
When I manually uploaded the file using aws s3 cp, I saw the following header info on the s3 object
$ aws s3api head-object --bucket bucketname --key epel-release-6-8.noarch.rpm { "AcceptRanges": "bytes", "ContentType": "binary/octet-stream", "LastModified": "Sat, 19 Sep 2015 03:39:13 GMT", "ContentLength": 14540, "ETag": "\"2cd0ae668a585a14e07c2ea4f264d79b\"", "Metadata": {}}
So, the MD5 IS in there... IF I use a program/command that sets it in the metadata.
Back to my problem at hand... how would I know if I already downloaded the file? What are my options?
- Figure out some sort of script to calculate the md5 sum of the file. This would require me assuming the number of multi-part chunks
- Always make our upload process either not use multi-part uploads (keeping the ETag equal to the MD5sum) or use some tool or manually set the metadata to contain an md5sum
- Pull out the ETag value when I download the file, and store an additional file with my downloaded s3 file (e.g. if I have s3://bucket/foo.tar.gz, pull out it's ETag and write it to foo.tar.gz.etag after a successful download)
All three have disadvantages.
#1 - This script has to assume or calculate multi-part upload chunk size. It is explored in some of the answers at this StackOverflow post.
#2 - This requires our uploads to have happened a certain way. If someone circumvents the standard process for uploading (uses a multipart upload, or uploads with the aws s3 cp instead of aws s3api put-object), then we would always download the item.
# 3 - This requires us saving a separate metadata file alongside the file download. If the application we are downloading the file for is sensitive to additional files hanging around, this may interfere. there IS a big plus in this case though.
aws s3api get-object has a helpgul argument....
--if-none-match (string) Return the object only if its entity tag
(ETag) is different from the one specified, otherwise return a 304 (not
modified).
If I use that, the s3 call would skip downloading the file if the ETag matches.
Also, with option 3... how do I do it in puppet? Do I have some clever chaining of exec resources? Do I create a resource type that utilizes the aws-ruby sdk?
Hrm, another post with ideas and options but no solutions.... I'll have to ponder how I should move forward with this, and fuel a future blog post!
Thanks for reading!
Monday, September 7, 2015
that's yum mmmy!
Hello everyone!
I've been pretty sparse lately, and today's topic is pretty light, but Today I Learned (TIL) that puppet has a yum repository resource! While I was trying to figure out if they had a augeas lens for the type of ini file that the format is stored in, I was very happy to find a native type in base puppet!
One feature that caught my eye is that there is a value of s3_enabled...
This has me intrigued, since we are working in AWS. Does this mean that we can create a repository as flat flies in an s3 bucket?
I found this amazing article on setting up s3 based yum repos using IAM authorization...
So, does it work!?
Yes and no.... According to this Pull Request, The plugin only supports IAM Signature version 2, which is only in place for older AWS regions. Newer regions only support IAM signature version 4.. Regions like China, Frankfurt, etc.. So only certain areas will be able to use the plugin as is.
I have tried duplicating the steps of the article on both a N. Virginia and a Frankfurt instance, and everything worked correctly in N. VA, and I had the same error as the pull request (400) when trying to use both yum-s3-iam and yum-s3-plugin. I have a really rough github project here which I used to aid my setup. I had to 'yum install -y git puppet3', clone my repository, and run my init script, then run sudo puppet apply ~/s3-repo-sandbox/s3_plugin.pp to apply my changes. I had pre-setup a bucket named dawiest-repo, in which I placed a noarch repository created similar to the above article.
Assuming you can get the above plugin to work for your region..... how can you make sure your repos are set up before any packages are installed? You could directly add require parameters to each package that needs it, but it is probably better to use the 'spaceship operator' to collect all the references and create the require entries for you!
http://serverfault.com/a/461869
Also, this article give a good description of the process needed for setting up gpg keys for your repo!
I've been pretty sparse lately, and today's topic is pretty light, but Today I Learned (TIL) that puppet has a yum repository resource! While I was trying to figure out if they had a augeas lens for the type of ini file that the format is stored in, I was very happy to find a native type in base puppet!
One feature that caught my eye is that there is a value of s3_enabled...
s3_enabled
(Property: This attribute represents concrete state on the target system.)
Access the repository via S3. Valid values are: False/0/No or True/1/Yes. Set this to
absent to remove it from the file completely.
Valid values are
absent. Values can match /^(True|False|0|1|No|Yes)$/i.This has me intrigued, since we are working in AWS. Does this mean that we can create a repository as flat flies in an s3 bucket?
I found this amazing article on setting up s3 based yum repos using IAM authorization...
So, does it work!?
Yes and no.... According to this Pull Request, The plugin only supports IAM Signature version 2, which is only in place for older AWS regions. Newer regions only support IAM signature version 4.. Regions like China, Frankfurt, etc.. So only certain areas will be able to use the plugin as is.
I have tried duplicating the steps of the article on both a N. Virginia and a Frankfurt instance, and everything worked correctly in N. VA, and I had the same error as the pull request (400) when trying to use both yum-s3-iam and yum-s3-plugin. I have a really rough github project here which I used to aid my setup. I had to 'yum install -y git puppet3', clone my repository, and run my init script, then run sudo puppet apply ~/s3-repo-sandbox/s3_plugin.pp to apply my changes. I had pre-setup a bucket named dawiest-repo, in which I placed a noarch repository created similar to the above article.
Assuming you can get the above plugin to work for your region..... how can you make sure your repos are set up before any packages are installed? You could directly add require parameters to each package that needs it, but it is probably better to use the 'spaceship operator' to collect all the references and create the require entries for you!
http://serverfault.com/a/461869
Although stages can handle this and so can specific yum repo dependencies, better is to declare the relationship generically.Just putYumrepo <| |> -> Package <| provider != 'rpm' |>in your puppet manifest.node default { Yumrepo <| |> -> Package <| provider != 'rpm' |> }This makes it so that all yumrepo types will get processed before any packages that don't have 'rpm' as their provider. That latter exclusion is so that I can use the (for example) epel-release RPM package to help install the yum repo.
Also, this article give a good description of the process needed for setting up gpg keys for your repo!
Friday, September 4, 2015
Hi everyone...
Felt like installing macvim... according to the internet, it would be as simple as 'brew install macvim'.
Oh, it wants the full XCode package, but I've just installed the CLI tools... lets see if there is a binary package in Cask?
Bingo... thanks Cask folks!
Felt like installing macvim... according to the internet, it would be as simple as 'brew install macvim'.
bash-3.2$ brew install macvimmacvim: A full installation of Xcode.app is required to compile this software.Installing just the Command Line Tools is not sufficient.Xcode can be installed from the App Store.Error: An unsatisfied requirement failed this build.
Oh, it wants the full XCode package, but I've just installed the CLI tools... lets see if there is a binary package in Cask?
bash-3.2$ brew cask install macvim --override-system-vim==> Downloading https://github.com/macvim-dev/macvim/releases/download/snapshot-77/MacVim-snapshot-77.tbz######################################################################## 100.0%==> Symlinking App 'MacVim.app' to '/Users/admin/Applications/MacVim.app'==> Symlinking Binary 'mvim' to '/usr/local/bin/mvim'🍺 macvim staged at '/opt/homebrew-cask/Caskroom/macvim/7.4-77' (1906 files, 35M)
Bingo... thanks Cask folks!
Saturday, August 22, 2015
Big trouble in Little OS X
Hi everyone!
Much to my excitement, a nearby school was selling off all of their old macbook to upgrade to new ones. That means I scored myself a 2012 MacBook Pro with i5, 4G of ram, for less than $200.
How about I start playing around with my usual set of tools (Docker, Vagrant, etc..)... oh, but I remember hearing about a package manager..... How to install Docker with Homebrew...
Homebrew! That's what it was! I set myself up a non-admin user, use the admin user to install homebrew, give myself sudo privs, then I'm off to the races! Ok, now I need to install Cask! No big deal! I've got this nifty package manager and a command to install it!
Oh, what is this? When I try to run the install command, I see the following...
It helpfully pops up a prompt to Get XCode or Install the XCode CLI tools... It pops up an aggrement, and then gets about 50% of the way though 'Downloading Software' and the time goes from 30min to 45min to 'About an Hour' and it just sits there until we see 'Failed due to network error'. I'm assuming there is some hard-coded url in the xcode-select command that is no longer being served by apple.
Seeing similar issues to a post mentioned in this thread.
I noticed that the list of tools given at osxdaily is mostly present in my /usr/bin directory. I created a softlink from /usr/bin to /Library/Developer/CommandLineTools/usr/bin, tried my brew install caskroom/cask/brew-cask call again, and nothing.... it just hangs.
OK... so I remove my softlink, and try following some other advise I had seen... to install all of XCode and use that to download the right CLI tools... I hop on over to the App Store and try to install it... I see 1 Update available, for Command Line Tools (OS X 10.9) 6.2. I click update, wait a while, and it says 'installed' next to it. I give my machine a reboot, try to do the brew install for cask again, and see the same problem!
So... I happened to see the command 'brew doctor'. I ran that, and it said that I didn't have git installed, and that my /usr/local/bin was after /usr/bin on my path, which means the things brew installs will resolve after the system installed versions.
I simply created
Much to my excitement, a nearby school was selling off all of their old macbook to upgrade to new ones. That means I scored myself a 2012 MacBook Pro with i5, 4G of ram, for less than $200.
How about I start playing around with my usual set of tools (Docker, Vagrant, etc..)... oh, but I remember hearing about a package manager..... How to install Docker with Homebrew...
Homebrew! That's what it was! I set myself up a non-admin user, use the admin user to install homebrew, give myself sudo privs, then I'm off to the races! Ok, now I need to install Cask! No big deal! I've got this nifty package manager and a command to install it!
Oh, what is this? When I try to run the install command, I see the following...
bash-3.2$ brew install caskroom/cask/brew-cask
==> Tapping caskroom/cask
xcode-select: note: no developer tools were found at '/Applications/Xcode.app', requesting install. Choose an option in the dialog to download the command line developer tools.
Error: Failure while executing: git clone https://github.com/caskroom/homebrew-cask /usr/local/Library/Taps/caskroom/homebrew-cask --depth=1
bash-3.2$ git clone https://github.com/caskroom/homebrew-cask /usr/local/Library/Taps/caskroom/homebrew-cask --depth=1
xcode-select: note: no developer tools were found at '/Applications/Xcode.app', requesting install. Choose an option in the dialog to download the command line developer tools.
It helpfully pops up a prompt to Get XCode or Install the XCode CLI tools... It pops up an aggrement, and then gets about 50% of the way though 'Downloading Software' and the time goes from 30min to 45min to 'About an Hour' and it just sits there until we see 'Failed due to network error'. I'm assuming there is some hard-coded url in the xcode-select command that is no longer being served by apple.
Seeing similar issues to a post mentioned in this thread.
I noticed that the list of tools given at osxdaily is mostly present in my /usr/bin directory. I created a softlink from /usr/bin to /Library/Developer/CommandLineTools/usr/bin, tried my brew install caskroom/cask/brew-cask call again, and nothing.... it just hangs.
OK... so I remove my softlink, and try following some other advise I had seen... to install all of XCode and use that to download the right CLI tools... I hop on over to the App Store and try to install it... I see 1 Update available, for Command Line Tools (OS X 10.9) 6.2. I click update, wait a while, and it says 'installed' next to it. I give my machine a reboot, try to do the brew install for cask again, and see the same problem!
So... I happened to see the command 'brew doctor'. I ran that, and it said that I didn't have git installed, and that my /usr/local/bin was after /usr/bin on my path, which means the things brew installs will resolve after the system installed versions.
I simply created
bash-3.2$ cat ~/.bash_profile
export PATH="/usr/local/bin:$PATH"
and did a 'brew install git'
That allowed me to get a little bit further... but I still hit an XCode CLI wall!
==> Installing brew-cask from caskroom/homebrew-cask
Error: The following formula:
brew-cask
cannot be installed as a a binary package and must be built from source.
To continue, you must install Xcode from:
https://developer.apple.com/downloads/
or the CLT by running:
xcode-select --install
So... It looks like I'm stuck upgrading the OS!
Even though I couldn't solve my actual problem, I hope some of my attempts at fixing my problem may be helpful for someone else!
Monday, August 3, 2015
TIL - paste!
Hi everyone!
Today, I was helping a co-worker with a script. He needed to find some set of directories, add /*.jar to the end of each, and put them together in a single line as coma-separated values.
Enter paste! (Funny thought, typing 'man paste' into google turned out much better than I thought it would!)
Say we had a list of all the files on my RaspberryPi's home directory, and we wanted to put them together as a comma separated list... We would simply pipe them through paste with the --delimiters=, and --serial flags set.
$ ls ~/Desktop/ | paste -d, -s
debian-reference-common.desktop,idle3.desktop,idle.desktop,lxterminal.desktop,midori.desktop,ocr_resources.desktop,paste.out,pistore.desktop,python-games.desktop,scratch.desktop,shutdown.desktop,sonic-pi.desktop,wolfram-language.desktop,wolfram-mathematica.desktop,wpa_gui.desktop
Today, I was helping a co-worker with a script. He needed to find some set of directories, add /*.jar to the end of each, and put them together in a single line as coma-separated values.
Enter paste! (Funny thought, typing 'man paste' into google turned out much better than I thought it would!)
Say we had a list of all the files on my RaspberryPi's home directory, and we wanted to put them together as a comma separated list... We would simply pipe them through paste with the --delimiters=, and --serial flags set.
$ ls ~/Desktop/ | paste -d, -s
debian-reference-common.desktop,idle3.desktop,idle.desktop,lxterminal.desktop,midori.desktop,ocr_resources.desktop,paste.out,pistore.desktop,python-games.desktop,scratch.desktop,shutdown.desktop,sonic-pi.desktop,wolfram-language.desktop,wolfram-mathematica.desktop,wpa_gui.desktop
Even though I've been using linux since about 2003, I feel like I stumble onto little nuggets like this pretty often!
Friday, July 31, 2015
AWS Tags as Facter facts
Hello everyone!
I hate it when I am looking for a solution, find other people online asking for the same solution... figure it out myself, and then the comments section is closed on the page that I found, so I can't even help anyone else in the future that stumbles onto that page....
I was browsing around, trying to figure out how to adopt the Roles and Profiles pattern to our puppet configuration on AWS, when I stumbled across this post.
http://sorcery.smugmug.com/2013/01/14/scaling-puppet-in-ec2/
After spending a while poking around at the AWS CLI and looking for solutions, I found a few examples similar to the following stack overflow example around the web.
http://stackoverflow.com/a/7122649
Facter.add(:powerstates) do confine :kernel => 'Linux' setcode do Facter::Core::Execution.exec('cat /sys/power/states') end end
... or by directly passing your command as a string to the setcode block.
One thing of note... I am still very new to ruby, but I occasionally had issues with errors happening with my AWS CLI call, and that would cause ALL of my facts to fail to load. wrapping the entire thing with a rescue StandardError clause fixed it for now.
You can also reference other facts from within facter, so instead of pulling the value from ec2-metadata, I could get it from the built in ec2_instance_id fact that was already on my box (which I presume gets it from the same source)
Wrapping that all together, It would look something like the following...
begin
Facter.add(:tag_name) do confine :kernel => 'Linux'
tag = 'Name'
cmd = 'ec2-describe-tags --filter "resource-type=instance" --filter "resource-id=' + Facter.value(:ec2_instance_id) + ' --filter "key=' + tag + ' | cut -f5'
setcode do Facter::Core::Execution.exec(cmd)
end end
rescue StandardError
end
You can replace the tag 'Name' with any other tag that you have specified (Role, Env, Tier, etc...) and pull information from the tags assigned to your instance.
You'll just have to make sure you put your custom fact in a module that you'll deploy to the boxes that need to know that information. If you have some sort of base profile you are using, you could put it in it's lib/facter/ directory.
One thing of note... every time facter gathers facts, it's making a call to the AWS api... if you are pulling down information for multiple tags or multiple pieces of info for separate facts, it may be better to either cache the results of the call as unfiltered json and manipulate it from it's raw json inside some ruby code, or cache the value you get back from the call. I've also heard of people putting a proxy between themselves and the amazon API to mitigate the same calls happening over and over.
Another useful thing to point out. You don't really HAVE to make any calls to the API if you don't want to. You can manually create your own facter fact that is static to the box at creation time (in the case of AWS, in your user-data script). Since you won't typically design your individual VMs to gracefully change roles, and the role changes would probably also require security group changes, you may be able to just create a text file in /etc/facter/facts.d/ that would contain puppet_role=myrole, and then you could reference the fact $::puppet_role from facter.
I hope this is useful for someone, as I had a hard time tracking down this specific information when I was trying to solve the problem myself!
P.S.
Another note from the earlier linked Stackoverflow post...
I hate it when I am looking for a solution, find other people online asking for the same solution... figure it out myself, and then the comments section is closed on the page that I found, so I can't even help anyone else in the future that stumbles onto that page....
I was browsing around, trying to figure out how to adopt the Roles and Profiles pattern to our puppet configuration on AWS, when I stumbled across this post.
http://sorcery.smugmug.com/2013/01/14/scaling-puppet-in-ec2/
After spending a while poking around at the AWS CLI and looking for solutions, I found a few examples similar to the following stack overflow example around the web.
http://stackoverflow.com/a/7122649
ec2-describe-tags \
--filter "resource-type=instance" \
--filter "resource-id=$(ec2-metadata -i | cut -d ' ' -f2)" \
--filter "key=Name" | cut -f5Facter.add(:powerstates) do confine :kernel => 'Linux' setcode do Facter::Core::Execution.exec('cat /sys/power/states') end end
... or by directly passing your command as a string to the setcode block.
One thing of note... I am still very new to ruby, but I occasionally had issues with errors happening with my AWS CLI call, and that would cause ALL of my facts to fail to load. wrapping the entire thing with a rescue StandardError clause fixed it for now.
You can also reference other facts from within facter, so instead of pulling the value from ec2-metadata, I could get it from the built in ec2_instance_id fact that was already on my box (which I presume gets it from the same source)
Wrapping that all together, It would look something like the following...
begin
Facter.add(:tag_name) do confine :kernel => 'Linux'
tag = 'Name'
cmd = 'ec2-describe-tags --filter "resource-type=instance" --filter "resource-id=' + Facter.value(:ec2_instance_id) + ' --filter "key=' + tag + ' | cut -f5'
setcode do Facter::Core::Execution.exec(cmd)
end end
rescue StandardError
end
You can replace the tag 'Name' with any other tag that you have specified (Role, Env, Tier, etc...) and pull information from the tags assigned to your instance.
You'll just have to make sure you put your custom fact in a module that you'll deploy to the boxes that need to know that information. If you have some sort of base profile you are using, you could put it in it's lib/facter/ directory.
One thing of note... every time facter gathers facts, it's making a call to the AWS api... if you are pulling down information for multiple tags or multiple pieces of info for separate facts, it may be better to either cache the results of the call as unfiltered json and manipulate it from it's raw json inside some ruby code, or cache the value you get back from the call. I've also heard of people putting a proxy between themselves and the amazon API to mitigate the same calls happening over and over.
Another useful thing to point out. You don't really HAVE to make any calls to the API if you don't want to. You can manually create your own facter fact that is static to the box at creation time (in the case of AWS, in your user-data script). Since you won't typically design your individual VMs to gracefully change roles, and the role changes would probably also require security group changes, you may be able to just create a text file in /etc/facter/facts.d/ that would contain puppet_role=myrole, and then you could reference the fact $::puppet_role from facter.
I hope this is useful for someone, as I had a hard time tracking down this specific information when I was trying to solve the problem myself!
P.S.
Another note from the earlier linked Stackoverflow post...
In case you use IAM instead of explicit credentials, use these IAM permissions:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [ "ec2:DescribeTags"],
"Resource": ["*"]
}
]
}Saturday, July 25, 2015
Hello everyone!
This is mostly notes to myself after watching this talk (after DevOps Weekly told me about it in one of their emails). I found the following bits of info pretty interesting and wanted to begin to apply this to some of the things I've been working on.
https://puppetlabs.com/presentations/building-hyper-secure-vpc-aws-puppet
16:41 -> Created an puppet module to apply IS benchmarking
20:56 -> rsyslog => graylog2 to roll all of their logs into one place
23:35 -> Network traffic logging... AWS Security Groups and Network ACL's don't log anything, Needed to log all traffic going in and out on any level of the VPC
-> Puppet + IPTables +Rsyslog +Graylog2
28:26 -> Facter fact for determining zone with ugly regex... tag zone by IP address... same for 'tier'
31:00 -> greylog2 was really good, millions of events in, really fast.
32:40 -> Performance of large catalogs was bad with puppet 2.7, Hiera-Gpg is cumbersome
recursion to remove checksums on big directories
file { "/etc/somedir":
recurse => true,
ignore => ['work', 'temp', 'log'],
checksum -> none,
}
(you don't want checksums on tomcat work directories)
Hiera-GBG is cumbersome, they switched to a mysql hiera backend
34:45 -> cloudformation json is ugly...
CFNDSL = ruby DSL for CloudFormation templates https://github.com/howech/cfndsl
use for cloudformation template generatoin
'Ugly'
35:22 -> unified state and lifecycle management -> Doesnot exist...
37:13 -> One single truth source for
1. audit trail/logging
2. Instance status
3. App status
4. CRUD actions on the whole infrastructure
39:40 -> puppetlabs aquired cloudsmith... is that heading toward some unified state and lifecycle management?
40:50 -> CIS, tmp should be on a different disk, did some trickery to shuffle it around?
42:00 -> Switched from CIS application and snapshot of AMI to applying the CIS benchmark once a day and using all default AMI
-> That prevented people from taking a hardened base image and fudging something setup by CIS . Once every halfhour got to cumbersome
This is mostly notes to myself after watching this talk (after DevOps Weekly told me about it in one of their emails). I found the following bits of info pretty interesting and wanted to begin to apply this to some of the things I've been working on.
https://puppetlabs.com/presentations/building-hyper-secure-vpc-aws-puppet
16:41 -> Created an puppet module to apply IS benchmarking
20:56 -> rsyslog => graylog2 to roll all of their logs into one place
23:35 -> Network traffic logging... AWS Security Groups and Network ACL's don't log anything, Needed to log all traffic going in and out on any level of the VPC
-> Puppet + IPTables +Rsyslog +Graylog2
28:26 -> Facter fact for determining zone with ugly regex... tag zone by IP address... same for 'tier'
31:00 -> greylog2 was really good, millions of events in, really fast.
32:40 -> Performance of large catalogs was bad with puppet 2.7, Hiera-Gpg is cumbersome
recursion to remove checksums on big directories
file { "/etc/somedir":
recurse => true,
ignore => ['work', 'temp', 'log'],
checksum -> none,
}
(you don't want checksums on tomcat work directories)
Hiera-GBG is cumbersome, they switched to a mysql hiera backend
34:45 -> cloudformation json is ugly...
CFNDSL = ruby DSL for CloudFormation templates https://github.com/howech/cfndsl
use for cloudformation template generatoin
'Ugly'
35:22 -> unified state and lifecycle management -> Doesnot exist...
37:13 -> One single truth source for
1. audit trail/logging
2. Instance status
3. App status
4. CRUD actions on the whole infrastructure
39:40 -> puppetlabs aquired cloudsmith... is that heading toward some unified state and lifecycle management?
40:50 -> CIS, tmp should be on a different disk, did some trickery to shuffle it around?
42:00 -> Switched from CIS application and snapshot of AMI to applying the CIS benchmark once a day and using all default AMI
-> That prevented people from taking a hardened base image and fudging something setup by CIS . Once every halfhour got to cumbersome
Tuesday, July 7, 2015
Who zookeeps the zookeepers?
Hello everyone!
I am wondering if anyone in the DevOps community knows of a good way to manage Zookeeper instances in an autoscaling group on Amazon AWS... here's some background.
I am using puppet to manage the instances, with a custom fact based on a tag to set a 'role', using the roles and profiles pattern.
The zookeeper configuration file needs to know about all of the other instances available. Should I use a script run on the master (with the generate function) to pull down a list of EC2s in that scaling group using the aws command? Custom fact on the box (using a similar command)?
I did see a serverfault post on using puppetDB. We haven't used puppetdb yet in our environment, and due to security policies, it takes a while to add new software to our environment.
Does anyone have any other suggestions for managing the zookeeper config's list of servers?
I am wondering if anyone in the DevOps community knows of a good way to manage Zookeeper instances in an autoscaling group on Amazon AWS... here's some background.
I am using puppet to manage the instances, with a custom fact based on a tag to set a 'role', using the roles and profiles pattern.
The zookeeper configuration file needs to know about all of the other instances available. Should I use a script run on the master (with the generate function) to pull down a list of EC2s in that scaling group using the aws command? Custom fact on the box (using a similar command)?
I did see a serverfault post on using puppetDB. We haven't used puppetdb yet in our environment, and due to security policies, it takes a while to add new software to our environment.
Does anyone have any other suggestions for managing the zookeeper config's list of servers?
Friday, June 26, 2015
It's been a while....
Hello everyone!
I haven't posted in a while... I just wanted to keep you updated with what's been going on.
I accepted a different position where I work which deals with bringing a lot more devops practices where we are usually caught behind the times.
Trying to help spearhead a significant culture change to an entrenched industry though a pathfinding project working with automation, cloud technologies, and adapting a large legacy codebase has been a lot of fun and a lot of work!
Ontop of all of my extra time/work devoted to that, I've had some other issues come up in my life. I'll try to give more information about that in a future post, but with the above mentioned issues and the business of summer upon me... well, we have put other things higher on our priority list, and I haven't had as much time for the blog.
While i'm on that, here is my list of excuses!
I haven't posted in a while... I just wanted to keep you updated with what's been going on.
I accepted a different position where I work which deals with bringing a lot more devops practices where we are usually caught behind the times.
Trying to help spearhead a significant culture change to an entrenched industry though a pathfinding project working with automation, cloud technologies, and adapting a large legacy codebase has been a lot of fun and a lot of work!
Ontop of all of my extra time/work devoted to that, I've had some other issues come up in my life. I'll try to give more information about that in a future post, but with the above mentioned issues and the business of summer upon me... well, we have put other things higher on our priority list, and I haven't had as much time for the blog.
While i'm on that, here is my list of excuses!
- My Macbook from 2008 stopped booting!
- I visited my brother who sailed onboard Le' hermione from France to Yorktown, VA.
- I drove out to MI to visit my mother!
- I spent a week leaving work at a normal time (instead of putting in extra time working on my project) to help out with our local
- I'm a lazy bum who isn't blogging as much as I should!
Wednesday, May 6, 2015
How to pass a variable to a one line command.
Hi everyone!
Today I learned (while trying to create a Facter fact ) that if you need to run a one line command that requires an Environment variable set, it's not as straight forward as you would expect.
I started with the example from the Puppet Docs
This gave me the following output
I ran that, and got the same output as last time! But wait! if I reverse the order of the quotes...
Suddenly, it works!
One small problem... When I ran my actual command, it didn't work! It wasn't reading my variable! Now to model this...
And here is my updated fact.
When I run it again, I get the following output
That looks a lot better!
TL:DR. If you are trying to run a command inside of a fact, you need to make sure you export your variable so it passes to the scope of your script, and you probably have to wrap it in a subshell.
Today I learned (while trying to create a Facter fact ) that if you need to run a one line command that requires an Environment variable set, it's not as straight forward as you would expect.
I started with the example from the Puppet Docs
Facter.add(:rubypath) do
setcode 'which ruby'
end
This gave me the following output
dawiest@old-laptop:~$ puppet apply -e 'notify{"Fact: $rubypath":} 'replaced the command with an example command to cover my case.
Notice: Compiled catalog for old-laptop in environment production in 0.10 seconds
Notice: Fact: /usr/bin/ruby
Notice: /Stage[main]/Main/Notify[Fact: /usr/bin/ruby]/message: defined 'message' as 'Fact: /usr/bin/ruby'
Notice: Finished catalog run in 0.07 seconds
Facter.add(:example_fact) doAnd here is my output, what went wrong!?
setcode 'VAR=hello; echo $VAR'
end
dawiest@old-laptop:~$ puppet apply -e 'notify{"Fact: $example":} 'I figured that the variable declaration was being lost somewhere... how about I run it in a sub-shell?
Notice: Compiled catalog for old-laptop in environment production in 0.11 seconds
Notice: Fact:
Notice: /Stage[main]/Main/Notify[Fact: ]/message: defined 'message' as 'Fact: '
Notice: Finished catalog run in 0.06 seconds
Facter.add(:example_fact) do
setcode 'sh -c "VAR=hello; echo $VAR" '
end
I ran that, and got the same output as last time! But wait! if I reverse the order of the quotes...
Facter.add(:example_fact) do
setcode "sh -c 'VAR=hello; echo $VAR' "
end
Suddenly, it works!
dawiest@old-laptop:~$ puppet apply -e 'notify{"Fact: $example":} '
Notice: Compiled catalog for old-laptop in environment production in 0.10 seconds
Notice: Fact: hello
Notice: /Stage[main]/Main/Notify[Fact: hello]/message: defined 'message' as 'Fact: hello'
Notice: Finished catalog run in 0.06 seconds
One small problem... When I ran my actual command, it didn't work! It wasn't reading my variable! Now to model this...
dawiest@old-laptop:~$ echo 'echo $VAR' > /tmp/example.sh && chmod u+x /tmp/example.sh
And here is my updated fact.
Facter.add(:example_fact) do
setcode "sh -c 'export VAR=hello; /tmp/example.sh' "
end
When I run it again, I get the following output
dawiest@old-laptop:~$ puppet apply -e 'notify{"Fact: $example":} 'So... the problem is that the variable was in scope for the echo call above, but it wasn't making it into my script..... time to export our variable!
Notice: Compiled catalog for old-laptop in environment production in 0.10 seconds
Notice: Fact:
Notice: /Stage[main]/Main/Notify[Fact: ]/message: defined 'message' as 'Fact: '
Notice: Finished catalog run in 0.06 seconds
dawiest@old-laptop:~$ puppet apply -e 'notify{"Fact: $example":} '
Notice: Compiled catalog for old-laptop in environment production in 0.10 seconds
Notice: Fact: hello
Notice: /Stage[main]/Main/Notify[Fact: hello]/message: defined 'message' as 'Fact: hello'
Notice: Finished catalog run in 0.06 seconds
That looks a lot better!
TL:DR. If you are trying to run a command inside of a fact, you need to make sure you export your variable so it passes to the scope of your script, and you probably have to wrap it in a subshell.
Saturday, April 4, 2015
Expecting more - gpg and expect
Hi everyone!
I recently needed to ssh to a machine, with a hard to remember password, and was unable to use ssh keys.
I had seen lots of examples for connecting though ssh that looked something like this...
Can you see something terribly wrong there? The password is stored in plain text in the file! Even setting restrictive file access permissions, that's not a very secure way of handling passwords.
I had read about gpg for storing/extracting secrets when I was learning puppet with the puppet 3 cookbook.
The steps to use gpg are as follows.
But, how do I tie that into an expect script for remotely logging in?
I initially found the exec statement for expect.
If I faked out getting the value directly, it would function as expected
After reading about 50 different stack overflow posts that mostly said 'Why don't you just use ssh keys' or just had examples in plain text, I FINALLY found a clue!
http://ubuntuforums.org/showthread.php?t=1790094
This poor guy got some bad advice, where they aren't using the exec statement (he's just assigning the command string to the password variable), but he had the part that I missed.... the --quiet and --no-tty arguments!
once I added those to my gpg command, everything finally worked!
Here is my final example script -
I recently needed to ssh to a machine, with a hard to remember password, and was unable to use ssh keys.
I had seen lots of examples for connecting though ssh that looked something like this...
#!/usr/bin/expect -f set timeout 60 spawn ssh username@machine1.domain.com expect "Password: " send "Password\r" send "\r" # This is successful. I am able to login successfully to the first machine # at this point, carry on scripting the first ssh session: send "ssh username@machine2.domain.com\r" expect ...
Can you see something terribly wrong there? The password is stored in plain text in the file! Even setting restrictive file access permissions, that's not a very secure way of handling passwords.
I had read about gpg for storing/extracting secrets when I was learning puppet with the puppet 3 cookbook.
The steps to use gpg are as follows.
#generate gpg key
temp@old-laptop:~$ gpg --gen-key
gpg (GnuPG) 1.4.16; Copyright (C) 2013 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
gpg: directory `/home/temp/.gnupg' created
gpg: new configuration file `/home/temp/.gnupg/gpg.conf' created
gpg: WARNING: options in `/home/temp/.gnupg/gpg.conf' are not yet active during this run
gpg: keyring `/home/temp/.gnupg/secring.gpg' created
gpg: keyring `/home/temp/.gnupg/pubring.gpg' created
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
Your selection? 1
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (2048)
Requested keysize is 2048 bits
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0)
Key does not expire at all
Is this correct? (y/N) y
You need a user ID to identify your key; the software constructs the user ID
from the Real Name, Comment and Email Address in this form:
"Heinrich Heine (Der Dichter) <heinrichh@duesseldorf.de>"
Real name: John Doe
Email address: jd@JohnDoe.com
Comment: example
You selected this USER-ID:
"John Doe (example) <jd@JohnDoe.com>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
You need a Passphrase to protect your secret key.
gpg: /home/temp/.gnupg/trustdb.gpg: trustdb created
gpg: key CFE3FAA2 marked as ultimately trusted
public and secret key created and signed.
gpg: checking the trustdb
gpg: 3 marginal(s) needed, 1 complete(s) needed, PGP trust model
gpg: depth: 0 valid: 1 signed: 0 trust: 0-, 0q, 0n, 0m, 0f, 1u
pub 2048R/CFE3FAA2 2015-04-04
Key fingerprint = 5851 BF85 33A2 01E5 895F 0BD2 34B0 F74F CFE3 FAA2
uid John Doe (example) <jd@JohnDoe.com>
sub 2048R/D7422C09 2015-04-04
#make file containing secret - please do it with an editor!
temp@old-laptop:~$ echo "1234" > ~/passfile
#encrypt file
temp@old-laptop:~$ gpg -e -r jd@JohnDoe.com ~/passfile
#remove plaintext file
temp@old-laptop:~$ ls
examples.desktop passfile passfile.gpg
temp@old-laptop:~$ rm passfile
#decrypt file
temp@old-laptop:~$ gpg -d ~/passfile.gpg
You need a passphrase to unlock the secret key for
user: "John Doe (example) <jd@JohnDoe.com>"
2048-bit RSA key, ID D7422C09, created 2015-04-04 (main key ID CFE3FAA2)
can't connect to `/run/user/1000/keyring-WFzMA0/gpg': Permission denied
gpg: can't connect to `/run/user/1000/keyring-WFzMA0/gpg': connect failed
gpg: encrypted with 2048-bit RSA key, ID D7422C09, created 2015-04-04
"John Doe (example) <jd@JohnDoe.com>"
1234
But, how do I tie that into an expect script for remotely logging in?
I initially found the exec statement for expect.
...It just didn't work properly for me. GPG would prompt me for my passphrase, but it would output some notification text and the key to my display, and while it would be stored in the variable, it confused expect and didn't properly spawn my ssh connection.
set password [exec gpg -d passfile.gpg]
...
If I faked out getting the value directly, it would function as expected
...Hrm... so what was I doing wrong? If I ran the same command and grabbed the output and redirected it to a file, it only contained my password.
set password [exec echo 1234]
...
gpg -d passfile.gpg > passfile.out
cat passfile.out
After reading about 50 different stack overflow posts that mostly said 'Why don't you just use ssh keys' or just had examples in plain text, I FINALLY found a clue!
http://ubuntuforums.org/showthread.php?t=1790094
This poor guy got some bad advice, where they aren't using the exec statement (he's just assigning the command string to the password variable), but he had the part that I missed.... the --quiet and --no-tty arguments!
once I added those to my gpg command, everything finally worked!
Here is my final example script -
#!/usr/bin/expect
set pass [exec gpg --decrypt --quiet --no-tty passfile.gpg]
spawn ssh temp@localhost
expect "password:"
send "$pass\r"
interact
Tuesday, March 3, 2015
What's the diff?
Hello everyone!
Have you ever had to compare two files? It's pretty easy on linux, there is a nice standard tool called 'diff' which can show you the differences between two text files. you also can use vimdiff to get a nicer way of seeing the differences, word by word instead of just line by line...
But what do you do if you need to diff two jar files? or if you want to diff two binary files while also displaying any strings that happen to be present?
Behold, a nice script that will let you use almost any tool on your path to output a representation of, well, ANYTHING, and then diff it with the tool of your choice. I may end up developing a version that could take different command line arguments to change things up, but right now I just edit the file and save it with different names, like jardiff.pl, binarydiff.pl, etc...
The $diff_tool is pretty self explanatory... you can use diff, vimdiff, or whatever diff program you have available.
To make sure we execute this with bash, we use bash -c \" $CMD_HERE \" to execute the command. We need to escape the quotes because we quoted the string to assign it to my $cmd.
The $diff_tool is pretty simple, we just envoke the command we specified earlier. In most cases, your diff tool expects to get two files to compare (you can use a tool like diff3 to do a three-way diff).
This brings us to the <( ... )operator. This executes the given command in a subshell, and output gets passed in as a file handle back to the original command. If we didn't do this, we would have to dump the output of each of the individual $vis_tool commands to a temp file, and then pass each file to the diff tool, and then clean up our temp files.
Finally, we actually execute the command with
This diff technique has been very helpful for me comparing all kinds of files, and I hope it can help you too!
Have you ever had to compare two files? It's pretty easy on linux, there is a nice standard tool called 'diff' which can show you the differences between two text files. you also can use vimdiff to get a nicer way of seeing the differences, word by word instead of just line by line...
But what do you do if you need to diff two jar files? or if you want to diff two binary files while also displaying any strings that happen to be present?
Behold, a nice script that will let you use almost any tool on your path to output a representation of, well, ANYTHING, and then diff it with the tool of your choice. I may end up developing a version that could take different command line arguments to change things up, but right now I just edit the file and save it with different names, like jardiff.pl, binarydiff.pl, etc...
jardiff.pl
#!/usr/bin/perl -w use strict; use warnings; use diagnostics; my $left = shift(); my $right = shift(); die unless ((-e $left) and (-e $right)); my $vis_tool = "jar -tf"; my $diff_tool = "vimdiff"; my $cmd="bash -c \"$diff_tool <($vis_tool $left) <$vis_tool $right)\""; exit system($cmd);Lets go over what is going on with each line...
#!/usr/bin/perl -w use strict; use warnings; use diagnostics;A good way to start out perl scripts, first line tells your shell what program to execute, and the rest of the lines are good ways of checking yourself if you make a mistake.. giving useful parsing error messages, enforcing stricter syntax, etc..
my $left = shift(); my $right = shift();This brings the 1st and 2nd arguments off the command line and stores them in the $left and $right values.
die unless ((-e $left) and (-e $right));
This line exits the script if both the left and right arguments do not exist as files on your system. I should add a usage statement to make things easier.
my $vis_tool = "jar -tf"; my $diff_tool = "vimdiff";Here is where our choices come in. In this instance, our visualization tool is 'jar -tf', which lists the contents of a jar specified by the file you pass to the command. If you also care about the dates and timestamps, you can add the -v command to also display that additional information.
The $diff_tool is pretty self explanatory... you can use diff, vimdiff, or whatever diff program you have available.
my $cmd="bash -c \"$diff_tool <($vis_tool $left) <$(vis_tool $right)\""; exit system($cmd);And this simply puts all the parts together, and runs it on the shell. Lets work left to right.
To make sure we execute this with bash, we use bash -c \" $CMD_HERE \" to execute the command. We need to escape the quotes because we quoted the string to assign it to my $cmd.
The $diff_tool is pretty simple, we just envoke the command we specified earlier. In most cases, your diff tool expects to get two files to compare (you can use a tool like diff3 to do a three-way diff).
This brings us to the <( ... )operator. This executes the given command in a subshell, and output gets passed in as a file handle back to the original command. If we didn't do this, we would have to dump the output of each of the individual $vis_tool commands to a temp file, and then pass each file to the diff tool, and then clean up our temp files.
Finally, we actually execute the command with
exit system($cmd);The other really useful way that I make this script is my 'binary' diff version. Most people would use hexdump to get a more diff-able version of a binary file, but I actually prefer to use xxd to get output that is both in hex and it attempts to 'stringify' as much of the binary as it can, and it shows it off to the side.
daryl$ xxd xpp3_min-1.1.4c.jar | head0000000: 504b 0304 0a00 0000 0000 12a5 6a35 0000 PK..........j5.. 0000010: 0000 0000 0000 0000 0000 0900 0000 4d45 ..............ME 0000020: 5441 2d49 4e46 2f50 4b03 040a 0000 0008 TA-INF/PK....... 0000030: 0011 a56a 35e5 823f 7b5e 0000 006a 0000 ...j5..?{^...j.. 0000040: 0014 0000 004d 4554 412d 494e 462f 4d41 .....META-INF/MA 0000050: 4e49 4645 5354 2e4d 46f3 4dcc cb4c 4b2d NIFEST.MF.M..LK- 0000060: 2ed1 0d4b 2d2a cecc cfb3 5230 d433 e0e5 ...K-*....R0.3.. 0000070: 72cc 4312 712c 484c ce48 5500 8a01 25cd r.C.q,HL.HU...%. 0000080: f48c 78b9 9c8b 5213 4b52 5374 9d2a 41ea ..x...R.KRSt.*A. 0000090: 4df5 0ce2 0d8c 7593 0ccc 1534 824b f314 M.....u....4.K..
This diff technique has been very helpful for me comparing all kinds of files, and I hope it can help you too!
Friday, February 27, 2015
Expect the unexpected!
I have been working with linux since Highschool (which isn't as long ago for me as it is for some), and I have just found a new command-line tool!
Expect
I was attempting to automate the 'store user config' process, and the weblogic.Admin way of doing it wasn't behaving(complaining about invalid pad in the key), so I was defaulting back to the WLST command. I ran into the same problem described here. Since in my specific scenario, I needed some environment configuration that didn't translate properly, I needed a way to execute it directly in my bash script.
Using the following WLST script (here's the one from StackOverflow above)
After a coworker suggested "expect", I came up with the following solution...
The expect command will 'spawn' the java process. It will wait until it sees the "y or n" portion of output from the script, when it will then 'send' a y followed by a newline to the program.
The first line, 'set timeout -1' was because creating the key file takes longer then the default timeout in expect, so it would terminate early (leaving behind a 0 length userkey.secure file)
Expect
I was attempting to automate the 'store user config' process, and the weblogic.Admin way of doing it wasn't behaving(complaining about invalid pad in the key), so I was defaulting back to the WLST command. I ran into the same problem described here. Since in my specific scenario, I needed some environment configuration that didn't translate properly, I needed a way to execute it directly in my bash script.
Using the following WLST script (here's the one from StackOverflow above)
#storeUserConfig.py
connect(user1,p@ss,'t3://myhost:9999')
storeUserConfig(userConfigFile='userconfig.secure',userKeyFile='userkey.secure')
disconnect()
exit()yes | java -cp $PATH_TO_WEBLOGIC_JAR weblogic.WLST storeUserConfig.py"
and
java -cp $PATH_TO_WEBLOGIC_JAR weblogic.WLST storeUserConfig.py" << EOF
y
EOF
After a coworker suggested "expect", I came up with the following solution...
#createKeyAndConfig.sh
## Do some stuff to set up the env similar to weblogic's included stopWebLogic.sh
...
CMD="java -cp $PATH_TO_WEBLOGIC_JAR weblogic.WLST storeUserConfig.py"
expect -c "
set timeout -1
spawn \"$CMD\"
expect \"y or n\"
send \"y\r\"
expect eof
"The expect command will 'spawn' the java process. It will wait until it sees the "y or n" portion of output from the script, when it will then 'send' a y followed by a newline to the program.
The first line, 'set timeout -1' was because creating the key file takes longer then the default timeout in expect, so it would terminate early (leaving behind a 0 length userkey.secure file)
Subscribe to:
Posts (Atom)